
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 한화오션
- 모두를 위한 머신러닝
- sort
- softmax
- Neural Network
- SQL
- 시간초과
- Machine learning
- 모두를 위한 딥러닝
- sung kim
- 프로그래머스
- mysql
- join
- CSAP
- c++
- 알고리즘 고득점 kit
- 백준
- Programmers
- stl
- DFS
- deque
- deep learning
- TensorFlow
- Queue
- ML
- 정렬
- PIR
- 큐
- BOJ
- Linear Regression
- Today
- Total
목록AI/모두를 위한 ML (SungKim) (16)
hello, world!
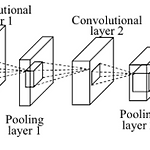 [ML lab 11-2] MNIST 99% with CNN
[ML lab 11-2] MNIST 99% with CNN
[Simple CNN] import numpy as np import tensorflow as tf import random mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_test = x_test / 255 x_train = x_train / 255 x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1) # one hot encode y data y_train = tf.keras.utils.to_categorical(y_train, 10) y_test = ..
 [ML lab 11-1] Tensorflow CNN Basics
[ML lab 11-1] Tensorflow CNN Basics
Convolutional Neural Networks 이미지나 텍스트 분류에서 좋은 성능을 발휘한다. 고양이의 뇌가 입력을 한번에 안받고 나누어 받는 것에서 착안했다. image에서 filter의 크기만큼 input x를 받아서 filter W로 하나의 값을 낸다. (Wx + b) ex.) filter 크기인 5*5만큼 읽은 input x가 x1, x2, x3, x4라면, filter w1, w2, w3, w4로 w1x1 + w2x2 + w3x3 + w4x4 + b 연산을 하여 one number를 출력한다. 같은 w값의 filter는 몇 칸씩 이동하며 이미지 전체를 읽는다. stride = 한번에 이동하는 칸 수 output size = (N - F) / (stride) + 1 stride가 커질수록 ..
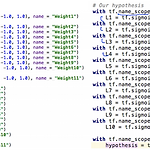 [ML lab 10] NN, ReLu, Xavier, Dropout, and Adam
[ML lab 10] NN, ReLu, Xavier, Dropout, and Adam
[Vanishing gradient] 위와 같이 9 layer 깊이 학습시켜보았다. poor results가 나왔다. 왜??? Backpropagation algorithm의 chain rule 때문에 그렇다. sigmoid function은 늘 0~1 사이의 값을 출력하기 때문에 layer가 깊어질수록 값이 작아진다. Vanishing gradient 발생! 경사도가 사라지는 현상이다. 첫 부분의 값이 최종 layer에 거의 영향을 미치지 못한다. 이 문제를 해결할 수 있을까? [Geoffrey Hinton] 1. We used wrong type of non-linearity 2. We initialized the weights in a stupid way 1. We used wrong type of..
TesnsorBoard 그래프를 통해 학습이 잘 이루어지고 있는지 한눈에 확인할 수 있다. [5 steps of using TensorBoard] 1. 어떤 tensor를 loging할 것인지 정한다. w2_hist = tf.summary.histogram("weights2", W2) cost_summ = tf.summary.scalar("cost", cost) 2. merge 한다. summary = tf.summary.merge_all() 3. file 위치를 적어 writer를 만들고 graph를 추가한다. # Create summary writer writer = tf.summary.FileWriter('./logs') writer.add_graph(sess.graph) 4. summery를 실행..
[Logistic regression for XOR] XOR 문제를 logistic regression으로 학습시킬 수 있을까? import tensorflow.compat.v1 as tf import numpy as np tf.disable_v2_behavior() x_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype = np.float32) y_data = np.array([[0], [1], [1], [0]], dtype = np.float32) X = tf.placeholder(tf.float32) Y = tf.placeholder(tf.float32) W = tf.Variable(tf.random_normal([2, 1]), name = 'weig..
Axis(축) 가장 바깥 []이 0번 axis이고 안쪽으로 들어갈수록 커진다. 가장 안쪽 []은 -1번이라고 하기도 한다. matmul() 등 matrix 연산을 할 때에는 shape을 보고 가능한지 주의해야한다. ex. (2, 2)와 (2,1)의 multiply는 가능하다. broadcasting (warning!) shape이 동일하지 않은 경우에 matrix 연산을 시도하면, 연산을 할 수 있도록 shape을 자동으로 맞추어 준다. reduce_mean() 항상 각 element가 float type이 되도록 주의해야 한다. 축(axis)을 무엇으로 정하는지에 따라 다른 값이 나온다. (축을 명시하지 않으면 모든 element의 평균을 구한다.) tf.reduce_mean([1, 2], axis =..
 [ML alb 07-2] Meet MNIST Dataset
[ML alb 07-2] Meet MNIST Dataset
import tensorflow as tf learning_rate = 0.001 batch_size = 100 training_epochs = 15 nb_classes = 10 # download mnist dataset mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() # normalizing data x_train, x_test = x_train / 255.0, x_test / 255.0 # change data shape print(x_train.shape) # (60000, 28, 28) x_train = x_train.reshape(x_train.shape[0], x_train.shap..
[내가 만든 모델이 얼마나 훌륭한지 어떻게 평가할까?] training datasets을 통해 평가하는 것은 좋은 방법이 아니다. dataset을 training set과 test set으로 나누는 것이 핵심! training dataset: 모델을 학습시킬 때 사용한다. test dataset: 학습된 모델의 성능을 계산할 때 사용한다. import tensorflow.compat.v1 as tf tf.disable_v2_behavior() # training data # 모델을 학습시킬 때만 사용 x_data = [[1, 2, 1], [1, 3, 2], [1, 3, 4], [1, 5, 5], [1, 7, 5], [1, 2, 5], [1, 6, 6], [1, 7, 7]] y_data = [[0, 0, ..