
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- PIR
- Programmers
- deque
- 큐
- 모두를 위한 머신러닝
- mysql
- Machine learning
- join
- c++
- sung kim
- ML
- deep learning
- TensorFlow
- SQL
- CSAP
- 정렬
- BOJ
- 프로그래머스
- stl
- 한화오션
- 시간초과
- Neural Network
- sort
- 백준
- DFS
- softmax
- Queue
- 알고리즘 고득점 kit
- Linear Regression
- 모두를 위한 딥러닝
- Today
- Total
hello, world!
[ML lab 10] NN, ReLu, Xavier, Dropout, and Adam 본문
[Vanishing gradient]
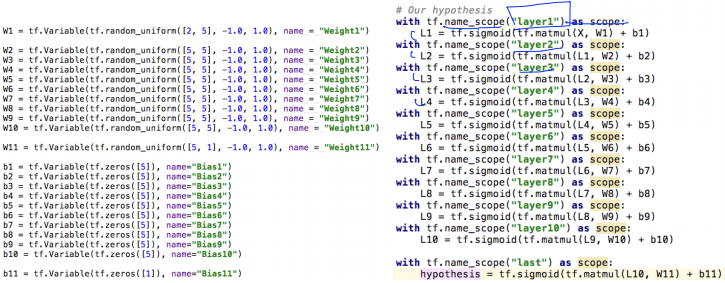
위와 같이 9 layer 깊이 학습시켜보았다.
poor results가 나왔다. 왜???
Backpropagation algorithm의 chain rule 때문에 그렇다.

sigmoid function은 늘 0~1 사이의 값을 출력하기 때문에 layer가 깊어질수록 값이 작아진다.

Vanishing gradient 발생!
경사도가 사라지는 현상이다. 첫 부분의 값이 최종 layer에 거의 영향을 미치지 못한다.
이 문제를 해결할 수 있을까?
[Geoffrey Hinton]
1. We used wrong type of non-linearity
2. We initialized the weights in a stupid way
1. We used wrong type of non-linearity
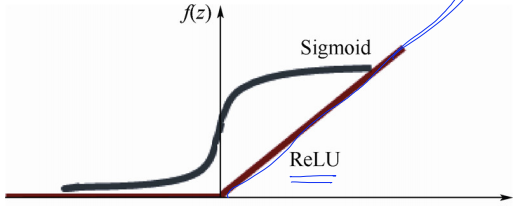
ReLU: Rectified Linear Unit
sigmoid 함수 대신 ReLU를 사용하자.
(마지막 layer는 0~1 사이의 값이 필요하기 때문에 sigmoid 함수를 사용)
2. We initialized the weights in a stupid way
초기값을 잘 주는 방법: RBM(Restrcited Boatman Machine) 사용
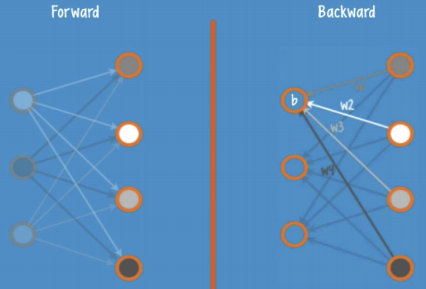
각 layer 마다 RBM을 사용해서 encode, decode를 반복해 weight의 초기값을 학습시킨다.
(forward와 backward 시 입력 X의 차이를 최소화하는 초기값 w를 둔다.)

그런데!
Good news: 복잡한 RBM을 사용하지 않고도 좋은 초기값을 줄 수 있다.
Xavier/He initialization
fan_in(입력)과 fan_out(출력)에 따라 초기값을 주는 방식이다.
[Outfitting]
training data로 실행시키면 정확도가 매우 높지만,
test data로 실행시키면 정확도가 떨어진다면!
해결책이 있을까?
Regularization

너무 큰 수의 w를 주지 않는다.
Dropout
random하게 특정 노드를 끊어버린다.
주의) training 할 때 -> dropout_rate: 0.5~0.7 정도
test 할 때 -> dropout_rate: 1 (전체)
Ensemble
여러 개의 학습모델을 두고 결과를 combine하여 예측하는 방식이다.
[NN for MNIST]
lab 07-2에서 실습해봤던 Softmax classifier로 MNIST 데이터베이스를 학습시켰던 모델의 정확도는 약 93%였다.
이번에는 Neural Network를 통해 학습시켜봤다.
import numpy as np
import random
import tensorflow as tf
random.seed(777) # for reproducibility
learning_rate = 0.001
batch_size = 100
training_epochs = 15
nb_classes = 10
(x_train, y_train), (x_test2, y_test) = tf.keras.datasets.mnist.load_data()
print(x_train.shape)
# reshape
x_train = x_train.reshape(x_train.shape[0], 28 * 28)
x_test = x_test2.reshape(x_test2.shape[0], 28 * 28)
# one hot 형태로 바꾼다
y_train = tf.keras.utils.to_categorical(y_train, nb_classes)
y_test = tf.keras.utils.to_categorical(y_test, nb_classes)
tf.model = tf.keras.Sequential()
tf.model.add(tf.keras.layers.Dense(input_dim=784, units=256, activation='relu')) # 256은 임의로 결정함
tf.model.add(tf.keras.layers.Dense(units=256, activation='relu'))
tf.model.add(tf.keras.layers.Dense(units=nb_classes, activation='softmax'))
tf.model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(lr=learning_rate), metrics=['accuracy'])
tf.model.summary()
tf.model.fit(x_train, y_train, batch_size=batch_size, epochs=training_epochs)
# predict 10 random hand-writing data
y_predicted = tf.model.predict(x_test)
for x in range(0, 10):
random_index = random.randint(0, x_test.shape[0]-1)
print("index: ", random_index,
"actual y: ", np.argmax(y_test[random_index]),
"predicted y: ", np.argmax(y_predicted[random_index]))
# evaluate test set
evaluation = tf.model.evaluate(x_test, y_test)
print('loss: ', evaluation[0])
print('accuracy', evaluation[1])input은 784(28*28)이고 마지막 layer의 output은 10이다.
그 사이 layer에서 노드 수는 임의로 정할 수 있는데, 위 코드에서는 256으로 정하고 relu 함수를 activation 함수로 썼다.
총 3단으로 구현했다.
[출력]
. . .
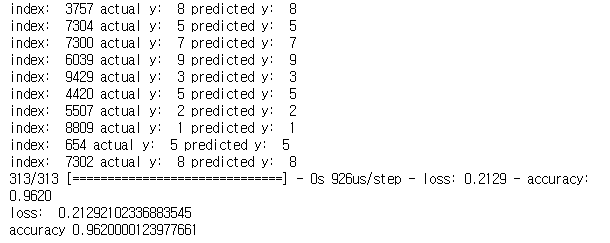
NN으로 학습시킨 결과 약 96%의 정확도가 나왔다.
[Xavier for MNIST]
위와 동일한 3단 NN을 통해 MNIST를 학습시키는데,
W를 Xavier normal initializer (=Glorot normal initializer)를 사용하여 초기화했다.
import numpy as np
import random
import tensorflow as tf
random.seed(777) # for reproducibility
learning_rate = 0.001
batch_size = 100
training_epochs = 15
nb_classes = 10
(x_train, y_train), (x_test2, y_test) = tf.keras.datasets.mnist.load_data()
print(x_train.shape)
x_train = x_train.reshape(x_train.shape[0], 28 * 28)
x_test = x_test2.reshape(x_test2.shape[0], 28 * 28)
y_train = tf.keras.utils.to_categorical(y_train, nb_classes)
y_test = tf.keras.utils.to_categorical(y_test, nb_classes)
tf.model = tf.keras.Sequential()
# Glorot normal initializer, also called Xavier normal initializer.
# see https://www.tensorflow.org/api_docs/python/tf/initializers
tf.model.add(tf.keras.layers.Dense(input_dim=784, units=256, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dense(units=256, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dense(units=nb_classes, kernel_initializer='glorot_normal', activation='softmax'))
tf.model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(lr=learning_rate), metrics=['accuracy'])
tf.model.summary()
history = tf.model.fit(x_train, y_train, batch_size=batch_size, epochs=training_epochs)
# predict 10 random hand-writing data
y_predicted = tf.model.predict(x_test)
for x in range(0, 10):
random_index = random.randint(0, x_test.shape[0]-1)
print("index: ", random_index,
"actual y: ", np.argmax(y_test[random_index]),
"predicted y: ", np.argmax(y_predicted[random_index]))
# evaluate test set
evaluation = tf.model.evaluate(x_test, y_test)
print('loss: ', evaluation[0])
print('accuracy', evaluation[1])[출력]
. . .

. . .
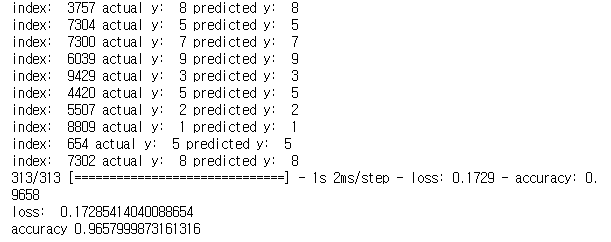
초반부터 loss(cost)가 현저히 낮다. 이것은 초기값이 알맞게 설정되었음을 나타낸다.
정확도도 더 높다.
[Deep NN for MNIST]
이전보다 노드 수를 wide하게(512개), layer를 deep하게(5 layer) 늘려서 구현해봤다.
import numpy as np
import random
import tensorflow as tf
random.seed(777) # for reproducibility
learning_rate = 0.001
batch_size = 100
training_epochs = 15
nb_classes = 10
(x_train, y_train), (x_test2, y_test) = tf.keras.datasets.mnist.load_data()
print(x_train.shape)
x_train = x_train.reshape(x_train.shape[0], 28 * 28)
x_test = x_test2.reshape(x_test2.shape[0], 28 * 28)
y_train = tf.keras.utils.to_categorical(y_train, nb_classes)
y_test = tf.keras.utils.to_categorical(y_test, nb_classes)
tf.model = tf.keras.Sequential()
# Glorot normal initializer, also called Xavier normal initializer.
# see https://www.tensorflow.org/api_docs/python/tf/initializers
tf.model.add(tf.keras.layers.Dense(input_dim=784, units=512, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dense(units=512, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dense(units=512, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dense(units=512, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dense(units=nb_classes, kernel_initializer='glorot_normal', activation='softmax'))
tf.model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(lr=learning_rate), metrics=['accuracy'])
tf.model.summary()
history = tf.model.fit(x_train, y_train, batch_size=batch_size, epochs=training_epochs)
# predict 10 random hand-writing data
y_predicted = tf.model.predict(x_test)
for x in range(0, 10):
random_index = random.randint(0, x_test.shape[0]-1)
print("index: ", random_index,
"actual y: ", np.argmax(y_test[random_index]),
"predicted y: ", np.argmax(y_predicted[random_index]))
# evaluate test set
evaluation = tf.model.evaluate(x_test, y_test)
print('loss: ', evaluation[0])
print('accuracy', evaluation[1])출력 결과, 정확도가 오히려 더 떨어진다.
overfitting이 발생한 것!!
해결해 보자.
[Dropout for MNIST]
import numpy as np
import random
import tensorflow as tf
random.seed(777) # for reproducibility
learning_rate = 0.001
batch_size = 100
training_epochs = 15
nb_classes = 10
drop_rate = 0.3
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
print(x_train.shape)
x_train = x_train.reshape(x_train.shape[0], 28 * 28)
x_test = x_test.reshape(x_test.shape[0], 28 * 28)
y_train = tf.keras.utils.to_categorical(y_train, nb_classes)
y_test = tf.keras.utils.to_categorical(y_test, nb_classes)
tf.model = tf.keras.Sequential()
# Glorot normal initializer, also called Xavier normal initializer.
# see https://www.tensorflow.org/api_docs/python/tf/initializers
tf.model.add(tf.keras.layers.Dense(input_dim=784, units=512, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dropout(drop_rate))
tf.model.add(tf.keras.layers.Dense(units=512, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dropout(drop_rate))
tf.model.add(tf.keras.layers.Dense(units=512, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dropout(drop_rate))
tf.model.add(tf.keras.layers.Dense(units=512, kernel_initializer='glorot_normal', activation='relu'))
tf.model.add(tf.keras.layers.Dropout(drop_rate))
tf.model.add(tf.keras.layers.Dense(units=nb_classes, kernel_initializer='glorot_normal', activation='softmax'))
tf.model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(lr=learning_rate), metrics=['accuracy'])
tf.model.summary()
history = tf.model.fit(x_train, y_train, batch_size=batch_size, epochs=training_epochs)
# predict 10 random hand-writing data
y_predicted = tf.model.predict(x_test)
for x in range(0, 10):
random_index = random.randint(0, x_test.shape[0]-1)
print("index: ", random_index,
"actual y: ", np.argmax(y_test[random_index]),
"predicted y: ", np.argmax(y_predicted[random_index]))
# evaluate test set
evaluation = tf.model.evaluate(x_test, y_test)
print('loss: ', evaluation[0])
print('accuracy', evaluation[1])[출력]
. . .
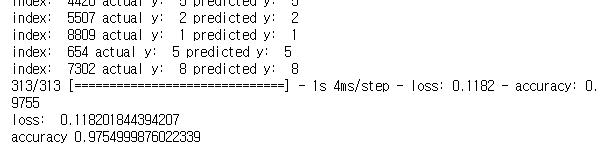
정확도가 증가한다!
[Optimizer]
그 외에도 optimizers를 사용해서 정확도를 높이는 방법이 있다.
가장 유명한 Adam Optimizer
# define cost/loss & optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=hypothesis, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)[Summary]

'AI > 모두를 위한 ML (SungKim)' 카테고리의 다른 글
| [ML lab 11-2] MNIST 99% with CNN (0) | 2021.02.24 |
|---|---|
| [ML lab 11-1] Tensorflow CNN Basics (0) | 2021.02.24 |
| [ML lab 09-2] Tensorboard (Neural Net for XOR) (0) | 2021.02.21 |
| [ML lab 09-1] Neural Net for XOR (0) | 2021.02.21 |
| [ML lab 08] Tensor Manipulation (0) | 2021.02.20 |

